Background
We considere a scenario where an autonomous platform that is searching an area for a target may observe unstable masonry or may need to travel over, by or through unstable rubble. One approach to allow the robot to safely navigate this challenge is to provide a general set of reactive behaviors that produce reasonable behavior under these uncertain and dynamic conditions. However, this approach may also produce behavior that works against the robots long-term goals, e.g., taking the quickest or safest route to a disaster victim or out of the building. In our work we investigate combining a behaviour-based approach with the Cognitive Robotics paradigm of rehearsal to produce a hybrid reactive-deliberative approach for this kind of scenario.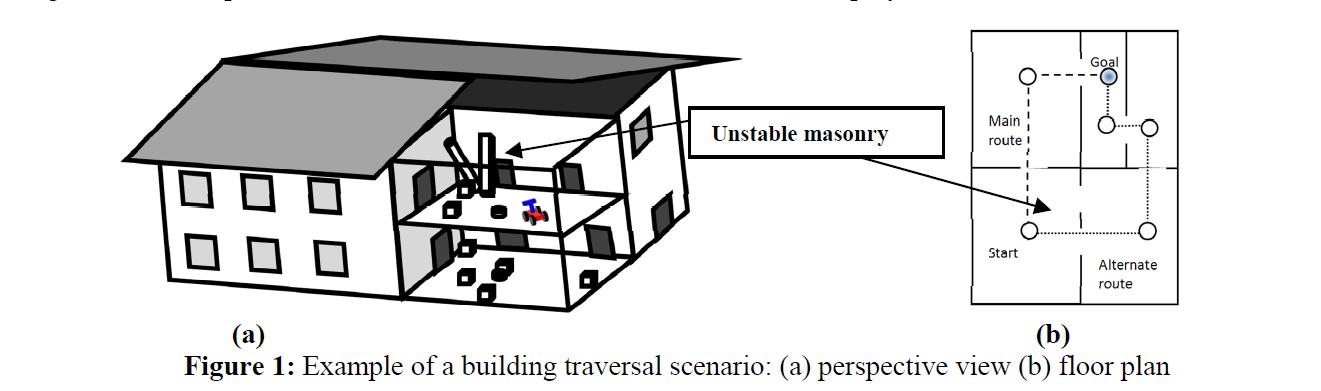 We propose an approach that leverages the state of the art in physics-engines for gaming so
that for a robot reasoning about what actions to take, perception itself becomes part of the problem solving process. A
physics-engine is used to numerically simulate outcomes of complex physical phenomena. The graphical image results
from the simulation are fused with the image information from robots visual sensing in a perceptual solution to the
prediction of expected situations.
Physics-engine software typically commits to a fairly standard taxonomy of object shapes and properties. To
avoid the issue of having a behaviour-based robot commit to or be limited by this exact same description of its
environment, we followed Macaluso and Chella (2007) in restricting the interaction between the simulation and robot to the
visual comparison of the output image from the simulation and the robots camera input image. This has the advantage of
keeping the robot control software and the simulation software quite separate (so it is easy to adopt new and better
physics-engine software as it becomes available). However, it also separates the two at a semantic level, so that the
robots understanding and representation of its environment can be quite different from that of the physics-engine.
Rather than looking for artificial landmarks to aid localization, as Macaluso and Chella did, our objective here is to
compare natural scene content between the real and synthetic images.
While fusing multiple real images poses some difficult challenges, fusing real and synthetic images posed a
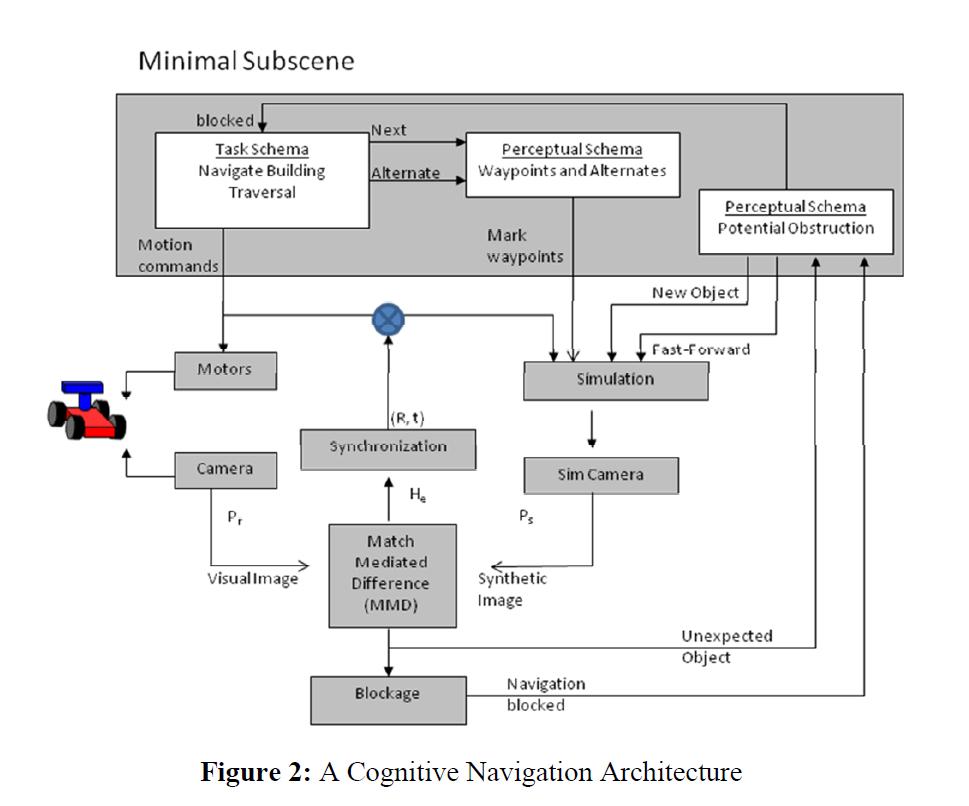
whole new set of problems. In Lyons et al. (2010) we introduced an approach, called the match-mediated difference (MMD), to
combining the information from real and synthetic images for static scenes containing real and/or simulated stationary
and moving objects. We leveraged Itti and Arbibs (2006) concept of the minimal subscene (developed for discourse
analysis) to capture how the robot modelled the scene being viewed, how it deployed the simulation and the MMD
operation to determine unexpected scene elements and how it requested and assimilated simulation predictions. The
minimal subscene contains a network of interconnected processes representing task and perceptual schemas (2003).
We propose an approach that leverages the state of the art in physics-engines for gaming so
that for a robot reasoning about what actions to take, perception itself becomes part of the problem solving process. A
physics-engine is used to numerically simulate outcomes of complex physical phenomena. The graphical image results
from the simulation are fused with the image information from robots visual sensing in a perceptual solution to the
prediction of expected situations.
Physics-engine software typically commits to a fairly standard taxonomy of object shapes and properties. To
avoid the issue of having a behaviour-based robot commit to or be limited by this exact same description of its
environment, we followed Macaluso and Chella (2007) in restricting the interaction between the simulation and robot to the
visual comparison of the output image from the simulation and the robots camera input image. This has the advantage of
keeping the robot control software and the simulation software quite separate (so it is easy to adopt new and better
physics-engine software as it becomes available). However, it also separates the two at a semantic level, so that the
robots understanding and representation of its environment can be quite different from that of the physics-engine.
Rather than looking for artificial landmarks to aid localization, as Macaluso and Chella did, our objective here is to
compare natural scene content between the real and synthetic images.
While fusing multiple real images poses some difficult challenges, fusing real and synthetic images posed a
whole new set of problems. In Lyons et al. (2010) we introduced an approach, called the match-mediated difference (MMD), to
combining the information from real and synthetic images for static scenes containing real and/or simulated stationary
and moving objects. We leveraged Itti and Arbibs (2006) concept of the minimal subscene (developed for discourse
analysis) to capture how the robot modelled the scene being viewed, how it deployed the simulation and the MMD
operation to determine unexpected scene elements and how it requested and assimilated simulation predictions. The
minimal subscene contains a network of interconnected processes representing task and perceptual schemas (2003).
Test World
A 15 room building was designed so as to present space for the robot to be confronted with challenges and be able to respond to the challenges by either continuing a traverse through the building or selecting an alternate path. Figure 7(a) shows the simulation model of the building from above. The entrance and exit doorways are on the bottom right and left. There are several large rooms with multiple doors which are the areas in which the robot can respond to challenges. There are also a number of smaller rooms which offer alternate routes through the building. Figure 7(b) shows the main waypoints (solid arrows) and alternate routes (dashed arrows). This information is stored in the waypoint schema.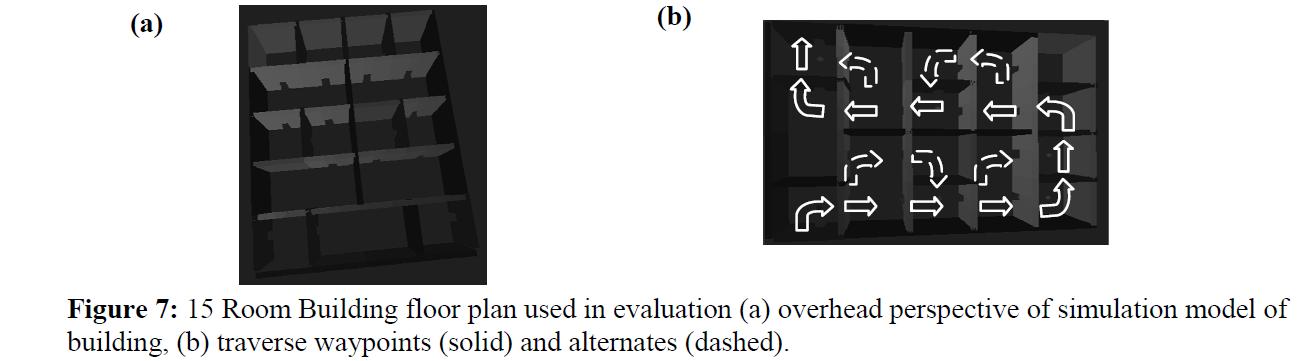 The robot makes the traverse of the building in either reactive mode (with the feedback from the simulation disengaged, so that no predictions are offered) or in cognitive mode (using predictions). For each run, the simulation building always appears the same. However, the real building can be altered dramatically as follows:
1. From one to four unstable columns of masonry can be placed as challenges, one in each of the large rooms.
2. The masonry can vary in color, in size and in initial velocity (how fast it falls).
3. The background wall colors can vary in color and texture.
The robot makes the traverse of the building in either reactive mode (with the feedback from the simulation disengaged, so that no predictions are offered) or in cognitive mode (using predictions). For each run, the simulation building always appears the same. However, the real building can be altered dramatically as follows:
1. From one to four unstable columns of masonry can be placed as challenges, one in each of the large rooms.
2. The masonry can vary in color, in size and in initial velocity (how fast it falls).
3. The background wall colors can vary in color and texture.
Videos!
- Small World Example: You will see the 'imagination' simulation screen on the upper left and the 'real' world on the bottom. There is a text screen on the right - you don't need to read that, its all diagnostics etc. In this example, you will see the robot navigate through the real world, its imagination following along, until it seems something unexpected - a block about to fall to block a door. You will see it being created in imagination, its effect simulated (and the 'real' world is stopped while this is shown to you -- otherwise it would be too fast to see), and detour taken because of the effect. The red sphere that appears in the 'imagination' marks where the robot is intending to move. This red marker makes it possible to do image processing to determine if a location is blocked or not (rather than 3D or sym bolic reasoning; faster!). cognitiveonly_smallbldg_1challenge.wmv.
- Reactive Only Example: You will see the real world on the top and the imagination on the bottom (no diagnostic screen for these longer runs). The aspect ratio is distorted, sorry. You will see the robot dash through the building and as it notices each falling block it tries to dodge it (using the Arkin (1998) potentiel field approach). Mostly it succeeds, but it depends on the size, shape and speed of the blocks of course - all randomly generated in these tests. In this run it makes it all the way to then end, and then gets clobbered! reactiveonly_4c_fail4.wmv.
- Cognitive Only Example: Different display again! The real world is bottom left; imagination bottom right and the diagnostic display is on the top. The comparison between real and expected scenes happens at every point, and when the falling block challenges are detected, you will see them recreated in simulation and their effect predicted. Of course it makes it to the end every time. cognitiveonly_text_4cs.wmv.
- Set ALLOWTOPICCHANGE = FRCVRoboticsGroup


| I | Attachment | History | Action | Size | Date | Who | Comment |
|---|---|---|---|---|---|---|---|
| |
archi.JPG | r1 | manage | 64.3 K | 2012-05-18 - 20:10 | DamianLyons | |
| |
cognitiveonly_smallbldg_1challenge.wmv | r1 | manage | 6498.0 K | 2012-05-18 - 20:17 | DamianLyons | |
| |
cognitiveonly_text_4cs.wmv | r1 | manage | 7701.3 K | 2012-05-18 - 20:38 | DamianLyons | |
| |
house.JPG | r1 | manage | 55.4 K | 2012-05-18 - 20:05 | DamianLyons | |
| |
reactiveonly_4c_fail4.wmv | r1 | manage | 2826.0 K | 2012-05-18 - 20:33 | DamianLyons | |
| |
rooms.JPG | r1 | manage | 47.0 K | 2012-05-18 - 20:16 | DamianLyons |
Topic revision: r1 - 2012-05-18 - DamianLyons

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Ideas, requests, problems regarding TWiki? Send feedback